データ解析を支援する機能を提供するライブラリである。
特に、数表および時系列データを操作するためのデータ構造と演算を提供する。
PandasはBSDライセンスのもとで提供されている。
(wikipediaより引用)
弊社では、PythonによるAI・IoT関連プロジェクトを行っていますが、
大量のCSVファイルを処理するためにPandasを使用しています。
その中でも、よく使用する操作について紹介したいと思います。
- CSVファイルの読み込みについて
- 条件に適合する行を抽出する
- 完全一致の抽出
- 特定の文字を含む抽出(部分一致抽出)
- 正規表現による抽出
- 式を用いた抽出
- CSVファイルを結合・連結する
- 結合・連結のパターンについて
- CSVファイルを結合する(内部結合)
- CSVファイルを連結する(縦方向)
1.CSVファイルの読み込みについて
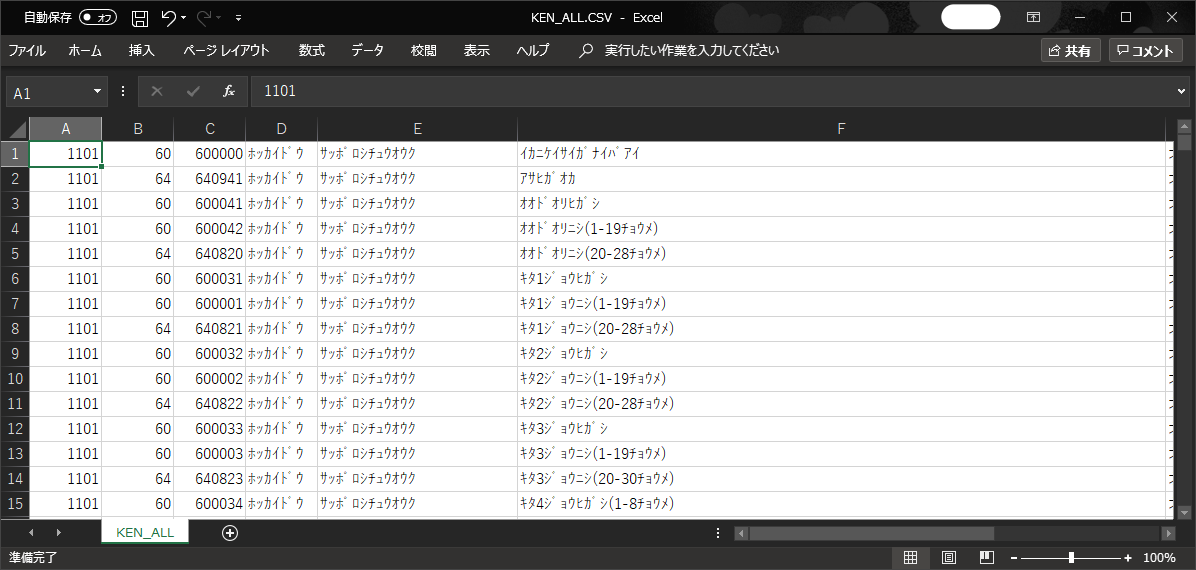
データ操作のために使用するデータは、郵便局が公開している郵便番号データ(CSV)を使用して行いたいと思います。
郵便番号データの各列は、下記のように定義されています。
CSV読み込みとオプションの説明
CSVファイルの読み込みは、pd.read_csv関数を利用して行うことが出来ます。
pd.read_csv関数には、読み込むCSVに合わせたオプションを指定する必要があります。
今回は使用する郵便番号データには、下記3つのオプションを指定して読み込みを行っていきます。
①読み込むCSVファイルの文字コードを指定します。UTF-8以外の文字コードの場合には、文字コードの指定が必要です。
②各列の名前を指定しています。読み込むCSVファイルに列の名前のデータを持っていない場合は、指定が必要です。
この名前は、列を指定したデータ操作を行う場合に使用する名前になります。
本項目を指定しない場合は、自動的に1から連番で数値の列名が割り当てられます。
③データの型を指定しています。先頭が0から始まる数値のみのデータがある場合などは、データ型が数値型と認識されて、
先頭の0が欠落してしまうため、明示的なデータ型の指定が必要です。
今回扱うデータは郵便番号であり、先頭0始まりのデータがあり得ます。
Pandasがデータ型を自動認識しないようにするため、明示的に指定を行っています。
1列目~9列目まではobject型(文字列型)、10列目~15列目まではuint8(符号なし8ビット整数型)で定義しています。
④ヘッダー行無しを指定しています。
Pandasは、読み込むCSVファイルの先頭行をヘッダー行として認識します。今回使用する郵便番号データには、
ヘッダー行が含まれていないため指定を行っています。
# CSV内のデータ名を定義
ken_all_names = [
"全国地方公共団体コード",
"(旧)郵便番号(5桁)",
"郵便番号(7桁)",
"都道府県名_カナ",
︙
]
# データ型を定義
data_types = {
"全国地方公共団体コード": 'object',
"(旧)郵便番号(5桁)": 'object',
"郵便番号(7桁)": 'object',
"都道府県名_カナ": 'object',
"市区町村名_カナ": 'object',
"町域名_カナ": 'object',
︙
"一つの郵便番号で二以上の町域を表す場合の表示": 'uint8',
"更新の表示": 'uint8',
"変更理由": 'uint8',
}
# CSVを読み込み
ken_all = pd.read_csv(os.path.join(base_dir, 'KEN_ALL.CSV'),
encoding='cp932', # エンコードを指定 ------①
names=ken_all_names, # 列名を指定 ------②
dtype=data_types, # データの型を指定 ------③
header=None) # ヘッダー行無しを指定 ----④
上記の『ken_all』変数に、読み込んだCSVファイルのデータが格納されています。
この変数を使って、データ操作を行っていきたいと思います。
2.条件に適合する行を抽出する
完全一致の抽出
都道府県名_カナが『フクオカケン』(福岡県)のデータのみ抽出します。
完全一致の条件でデータを抽出するには、==演算子を使用します。
# 検索条件に完全一致するデータ行を抽出
データフレーム[検索対象列名] == 検索文字列
処理結果は以下のようになりました。
福岡県(フクオカケン)に完全一致するデータが抽出されましたね。
# フクオカにマッチするデータ行を抽出
ken_all[ken_all['都道府県名_カナ'] == 'フクオカケン']
# 以下は処理結果
全国地方公共団体コード (旧)郵便番号(5桁) 郵便番号(7桁) 都道府県名_カナ 市区町村名_カナ 町域名_カナ 都道府県名_漢字 市区町村名_漢字
40101 800 8000000 フクオカケン キタキュウシュウシモジク イカニケイサイガナイバアイ 福岡県 北九州市門司区 以下に掲載がない場合
40101 800 8000045 フクオカケン キタキュウシュウシモジク アオバダイ 福岡県 北九州市門司区 青葉台
40101 80001 8000101 フクオカケン キタキュウシュウシモジク イカワ 福岡県 北九州市門司区 伊川
40101 800 8000041 フクオカケン キタキュウシュウシモジク イズミガオカ 福岡県 北九州市門司区 泉ケ丘
40101 800 8000048 フクオカケン キタキュウシュウシモジク イナヅミ 福岡県 北九州市門司区 稲積
...
前方一致の抽出
都道府県名が『フク』から始まるデータ行にマッチするデータのみ抽出します。
前方一致等の条件でデータを抽出するには、startswith関数を使用します。
期待値としては、福岡県、福島県、福井県の3県が表示される想定です。
# 検索条件から始まるデータ行を抽出
データフレーム[検索対象列名].str.startswith(検索文字列)
以下のように『フク』から始まるデータが表示されました。
# 都道府県名がフクから始まるデータ行を抽出
ken_all[ken_all['都道府県名_カナ'].str.startswith('フク')]
# 以下は抽出結果
全国地方公共団体コード (旧)郵便番号(5桁) 郵便番号(7桁) 都道府県名_カナ 市区町村名_カナ
07201 960 9600000 フクシマケン フクシマシ イカニケイサイガナイバアイ
07201 960 9608113 フクシマケン フクシマシ アサヒチョウ
07201 96021 9602156 フクシマケン フクシマシ アライ
07201 96021 9602102 フクシマケン フクシマシ アライキタ
07201 960 9608042 フクシマケン フクシマシ アラマチ
...
正しく3県のみが抽出されているか確認するため、都道府県名_カナでグループ化し、それぞれの重複した行をまとめてみます。
グループ化するには、groupby関数を使用します。
# 都道府県名_カナでグループ化し、それぞれの件数を表示
ken_all[ken_all['都道府県名_カナ'].str.startswith('フク')].groupby('都道府県名_カナ').size()
# 以下は抽出結果
都道府県名_カナ
フクイケン 2263
フクオカケン 3294
フクシマケン 3950
上記では、件数も含めて出力を行っていますが、件数が必要ない場合はunique関数を利用しても同様のことが出来ます。
# 重複した行をまとめる
データフレーム[列名].unique()
# 都道府県名_カナの重複した行をまとめる
ken_all[ken_all['都道府県名_カナ'].str.startswith('フク')]['都道府県名_カナ'].unique()
# 以下は抽出結果
array(['フクシマケン', 'フクイケン', 'フクオカケン'], dtype=object)
上記のように、3県で絞り込みがされていることが確認できましたね。
特定の文字を含む抽出(部分一致抽出)
都道府県名_カナ列に、『フ』が含まれるデータのみ抽出します。
特定の文字を含むデータのみを抽出する場合は、contains関数を使用します。
期待する結果は、以下の2府4県が絞り込まれるはずです。
- 大阪府(オオサカフ)
- 京都府(キョウトフ)
- 岐阜県(ギフケン)
- 福井県(フクイケン)
- 福岡県(フクオカケン)
- 福島県(フクシマケン)
# 検索条件から始まるデータ行を抽出
データフレーム[検索対象列名].str.contains(検索文字列)
都道府県名_カナでグループ化してカウントを表示しています。
2府4県が抽出されましたね。
# 都道府県名_カナ列に『フ』が含まれるデータのみ抽出
ken_all[ken_all['都道府県名_カナ'].str.contains('フ')].groupby('都道府県名_カナ').size()
# 以下は処理結果
都道府県名_カナ
オオサカフ 3846
キョウトフ 6658
ギフケン 3371
フクイケン 2263
フクオカケン 3294
フクシマケン 3950
正規表現による抽出
郵便番号(7桁)の1文字目と3文字目が0のデータのみ抽出します。
正規表現を使用した抽出は、完全一致でも使用したmatch関数を使用します。
# 検索条件に完全一致するデータ行を抽出
データフレーム[検索対象列名].str.match(正規表現)
正規表現指定を用いて、2文字目が『ウ』のデータを抽出してみます。
.(ドット)は任意の一文字を示しています。
この正規表現検索によって得られる結果の期待値は、東京都(トウキョウト)と高知県(コウチケン)となります。
ken_all[ken_all['都道府県名_カナ'].str.match('.ウ')]
以下のように期待値が得られました。
全国地方公共団体コード (旧)郵便番号(5桁) 郵便番号(7桁) 都道府県名_カナ 市区町村名_カナ 町域名_カナ
13101 100 1000000 トウキョウト チヨダク イカニケイサイガナイバアイ
13101 102 1020072 トウキョウト チヨダク イイダバシ
13101 102 1020082 トウキョウト チヨダク イチバンチョウ
13101 101 1010032 トウキョウト チヨダク イワモトチョウ
13101 101 1010047 トウキョウト チヨダク ウチカンダ
…
39201 780 7800000 コウチケン コウチシ イカニケイサイガナイバアイ
39201 780 7800054 コウチケン コウチシ アイオイチョウ
39201 780 7800813 コウチケン コウチシ アオヤギチョウ
39201 780 7800936 コウチケン コウチシ アカイシチョウ
39201 780 7808072 コウチケン コウチシ アケボノチョウ
…
ken_all[ken_all['都道府県名_カナ'].str.match('.ウ')].groupby('都道府県名_カナ').size()
都道府県名_カナ
コウチケン 1695
トウキョウト 3887
更に、正規表現指定を以下のように変更し、都道府県名にキを含み、末尾がトで終わる条件へと変更してみます。
*(アスタリスク)は0回以上の直前の指定の繰り返しを意味しています。
また、$(ダラー)は末尾の文字列の指定を行っています。この場合は、『ト』で終わることを指定しています。
ken_all[ken_all['都道府県名_カナ'].str.match('.*キ.*ト$')].groupby('都道府県名_カナ').size()
都道府県名_カナ
トウキョウト 3887
『トウキョウト』(東京都)のみが抽出されました。
上記の正規表現で、末尾の$を指定しない場合は、『キョウトフ』(京都府)も抽出対象になってしまいます。
ken_all[ken_all['都道府県名_カナ'].str.match('.*キ.*ト')].groupby('都道府県名_カナ').size()
都道府県名_カナ
キョウトフ 6658
トウキョウト 3887
式を用いた抽出
SQL文のようなクエリでAND条件、OR条件を指定しての抽出を行うこともできます。
式を用いた抽出には、query関数を使用します。
都道府県_カナが福岡(フクオカ)または佐賀(サガ)で、かつ”丁目を有する町域の場合の表示”列が該当(値が1)するデータのみ抽出するには、
下記で行うことが出来ます。
ken_all.query("(都道府県名_カナ=='フクオカケン' | 都道府県名_カナ=='サガケン') & 丁目を有する町域の場合の表示 == 1")
3.CSVファイルを結合・連結する
複数のCSVファイルを結合する操作についてご紹介したいと思います。
CSVファイルの結合は、特定の列や条件を利用してデータベースのように結合処理を行うことが出来ます。
結合・連結のパターンについて
Pandasでは、複数のCSVファイルを一つのデータの塊としてまとめることができます。
よく使用する結合や連結は、以下のように大きく2種類あります。
・結合:特定のキー情報が一致するデータを、1行のデータとしてまとめる操作(merge)
・連結:データをつなぎ合わせる(concat、join)
上記2種類のパターンのうち、代表的なものを1種類ずつ紹介したいと思います。
結合処理に使用するCSV読み込みとオプションの説明
使用するデータは、郵便番号データ(ken_all)と、ローマ字表記の郵便番号データ(ken_all_rome)の2つを利用したいと思います。
新たに利用するローマ字表記の郵便番号データは以下のようなデータとなります。
ローマ字表記の郵便番号データの各列は、下記のように定義されています。
ローマ字表記の郵便番号データを読み込むにあたり、下記のコードを追加しました。
本記事の初めに利用していた郵便番号データと異なる点は、下記の①です。
これから使用するローマ字表記の郵便番号データの全ての列を文字列として認識させるために、列のデータ型に'object'を利用しました。(①)
# ローマ字
ken_all_rome_column_names = [
"郵便番号(7桁)",
"都道府県名_漢字",
"市区町村名_漢字",
"町域名_漢字",
"都道府県名_ローマ",
"市区町村名_ローマ",
"町域名_ローマ",
]
# CSV読み込み
ken_all_rome = pd.read_csv(os.path.join(base_dir, 'KEN_ALL_ROME.CSV'),
encoding='cp932', # エンコード
names=ken_all_rome_column_names, # 列名を指定
dtype='object', # データタイプ -----①
header=None) # 1行目をヘッダーとして扱わない
CSVファイルを結合する(内部結合)
指定したデータのキー情報をもとに、双方のデータを一つのデータフレームとして取得することが出来ます。
結合には、複数のやり方があり、得られる結果が異なります。
- 内部結合(inner):両方のデータに含まれるキーだけを残す。どちらか一方にのみ含まれている場合は、削除される。
- 外部結合(outer):全てのキーを残す
- 左外部結合(left):1つ目のデータのキーを全て残す
- 右外部結合(right):2つ目のデータのキーを全て残す
下記のように、leftに1つ目のデータフレームを、rightに2つ目のデータフレームを設定します。
onには、結合に使用する列名を指定します。
howには、上記の結合のパターンを指定します。省略した場合は、内部結合が使用されます。
# 結合処理を行う
pd.merge(left, right, on='key', how='left')
今回は、内部結合のパターンをご紹介したいと思います。
日本語表記の郵便番号とローマ字表記の郵便番号データを内部結合します。
内部結合では、それぞれの郵便番号(7桁)が存在するデータのみが結合されます。
どちらか一方にのみ存在するデータは結合されません。
# CSVファイルを結合(内部結合)する
pd.merge(ken_all, ken_all_rome, on='郵便番号(7桁)', how='inner')
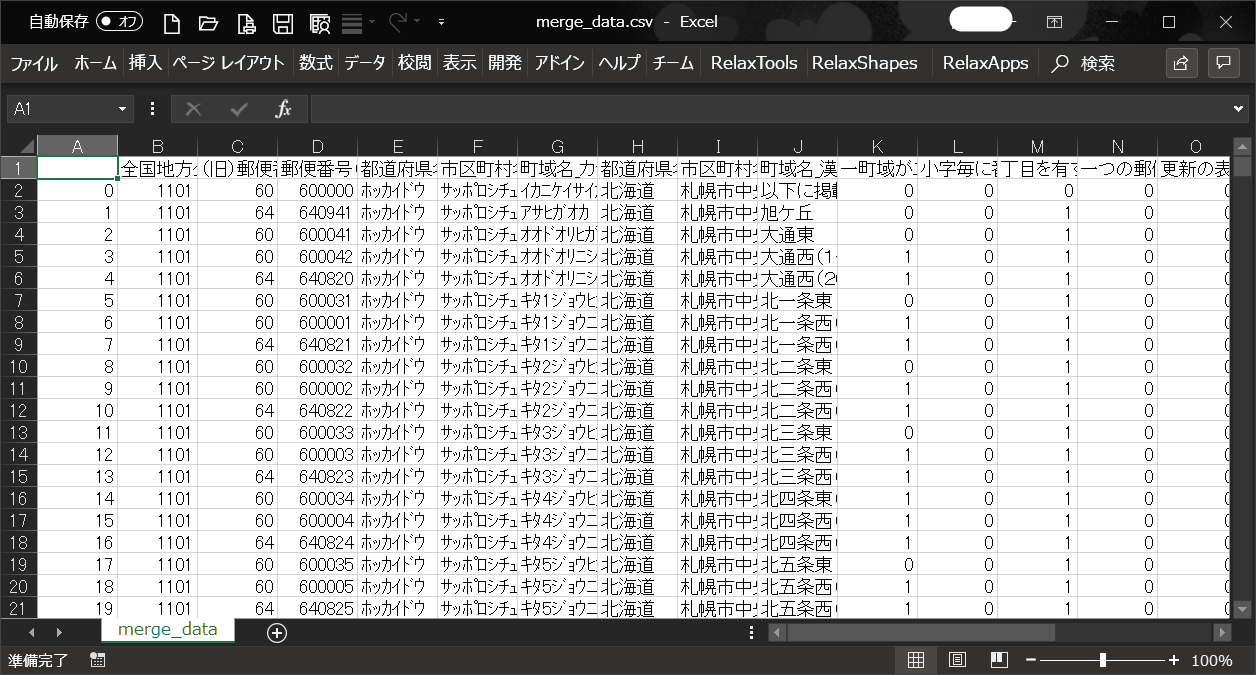
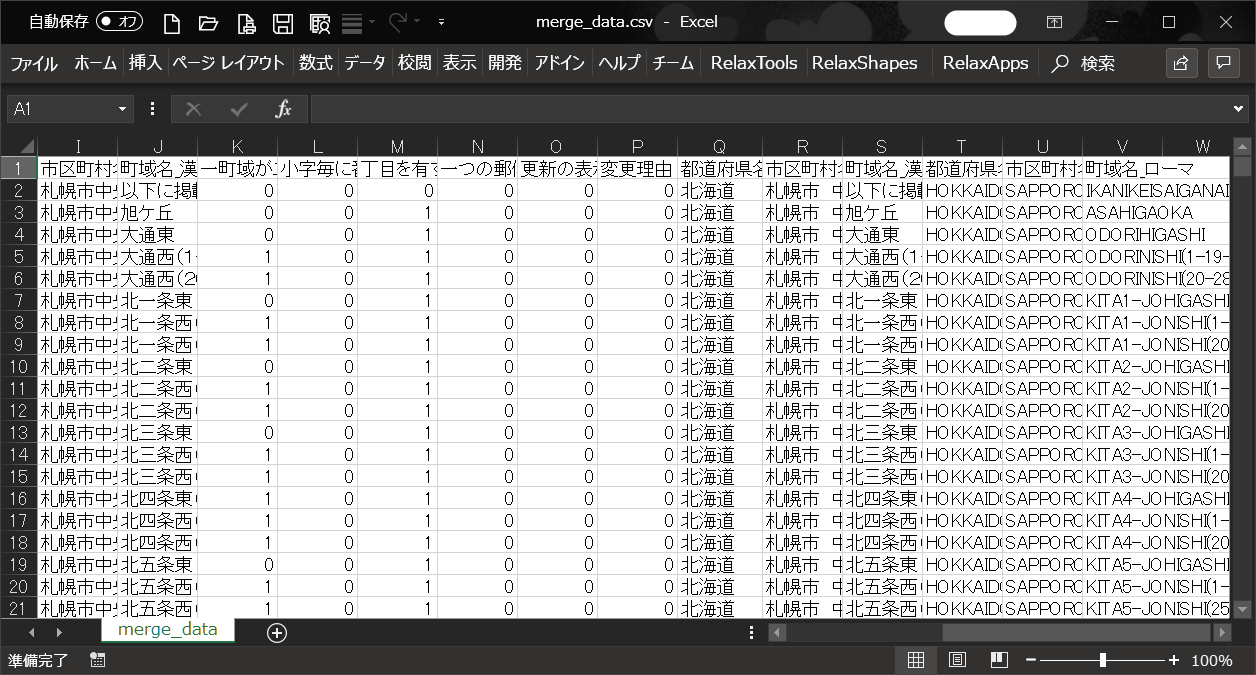
郵便番号(7桁)をキーとして、結合した結果が以下となります。
ファイルの左側(B列~P列)は、日本語表記の郵便番号データが出力されており、
ファイルの右側(Q列~V列)に、ローマ字表記の郵便番号データが出力されています。
■ファイルの左側を出力した図
■ファイルの右側を出力した図
CSVファイルを連結する(縦方向)
複数データをつなぎ合わせるような操作は、concat関数を用いて行います。
concat関数では、縦方向または横方向など軸となる方向を指定してつなぎ合わせることが出来ます。
連結するデータフレームに制限はなく、複数指定することができます。
# データを連結する
pd.concat([データフレーム1, データフレーム2, ...], axis=1)
オプションであるaxisには、軸を設定します。軸は、下記のように設定します。
未指定の場合は、縦方向に連結されます。
- 縦方向の連結:axis=0 または axis='index'
- 横方向の連結:axis=1 または axis='columns'
今回は、縦方向による連結処理をご紹介したいと思います。
連結処理に使用するCSV読み込み
本記事の『条件に適合する行を抽出する』の中では全国の郵便番号が全て格納されたものを利用していました。
連結処理の説明で使用するデータは、郵便番号データが県ごとにわかれたものを利用して行いたいと思います。
各都道府県毎に分かれたCSVファイルは、下記よりダウンロード可能です。
全国一括のCSVデータと異なる点は、県毎にデータが分かれていることのみで、データの形式は変わりありません。
以下のように、県ごとに分けてデータを読み込んだデータを連結していきます。
# 福岡県データを読み込み
fukuoka = pd.read_csv(os.path.join(base_dir, 'fukuoka.CSV'),
encoding='cp932',
names=column_names,
dtype=data_types,
header=None)
# 佐賀県データを読み込み
saga = pd.read_csv(os.path.join(base_dir, 'saga.CSV'),
encoding='cp932',
names=column_names,
dtype=data_types,
header=None)
縦方向に連結する
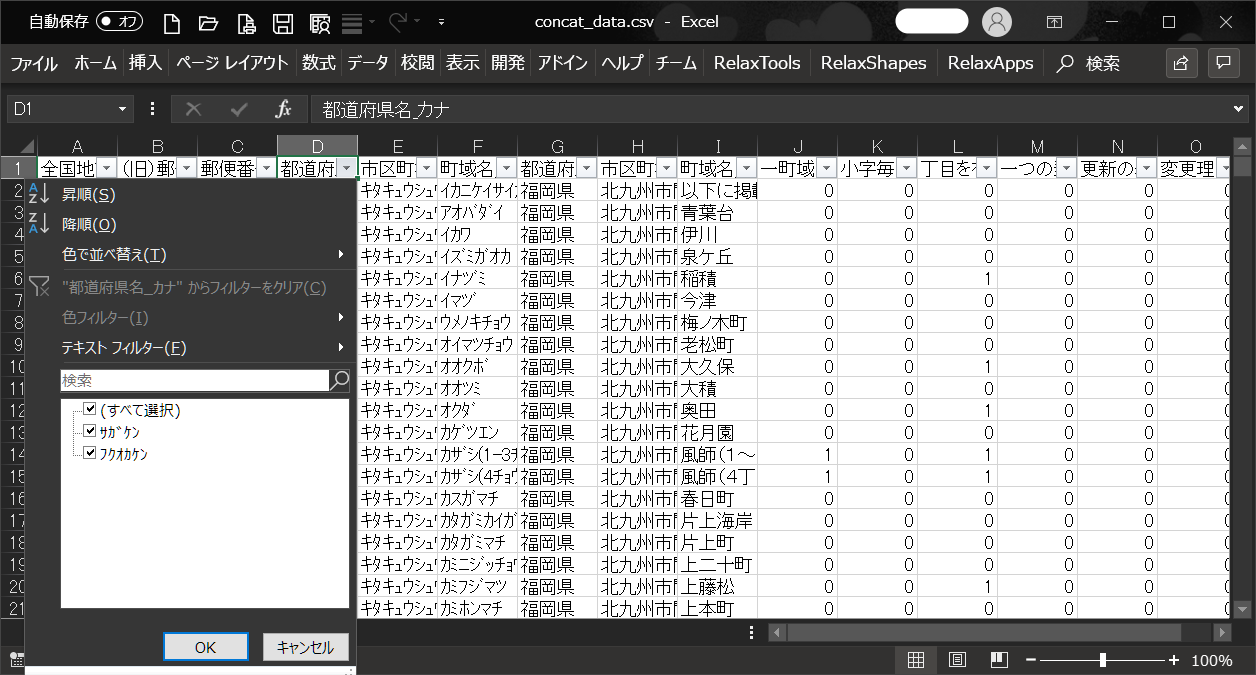
福岡県と佐賀県のデータを縦方向に連結します。
縦方向の連結では、福岡県と佐賀県それぞれに存在する行が連結され、それぞれの行データが足し合わされたデータを取得することが出来ます。
# 縦方向に連結する
pd.concat([fukuoka, saga], axis='index')
連結した結果は下記のように福岡県のデータの後に佐賀県のデータが連結されました。
フィルタの選択肢に、佐賀県(サガケン)と福岡県(フクオカケン)の2県が表示されています。
終わりに
Pandasにおけるデータ処理の基本的な操作をピックアップしてご紹介させて頂きましたが、いかがだったでしょうか。
少ないコード量で、効率的に処理が行えることが少しでもお分かり頂けたと思います。
今回紹介させて頂いたいくつかの例を通して、Pandasでこんなことが簡単に出来るのかと知って頂けましたら幸いです。
これだけ簡単にデータ操作ができれば、本当にやりたい事のみに注力することが出来ますね。
本当にやりたいことのみに注力できれば、おのずと生産性が上がってくるのではないでしょうか。
みなさんも生産性をガンガン上げていきましょう!
Python 関連技術記事
一緒に開発しませんか?
サンビット株式会社では、開発技術者を募集しています!
興味のある方はぜひお問い合わせください。